# All Libraries required for this lab are listed below. Already installed so this code block is commented out
pip install pandas==1.3.4
pip install scikit-learn==1.0.2
pip install numpy==1.21.6Linear Regression Model - MPG
Objectives
We will use car dataset to train a regression model that will predict the mileage of a car
Here is a list of Tasks we’ll be doing:
- Use Pandas to load data sets.
- Identify the target and features.
- Use Linear Regression to build a model to predict car mileage.
- Use metrics to evaluate the model.
- Make predictions using a trained model.
Jupyter notebook is found at: Building_and_training_a_model_using_Linear_Regression_1.ipynb
Setup
We will be using the following libraries:
pandasfor managing the data.sklearnfor machine learning and machine-learning-pipeline related functions.
Install Libraries
Suppress Warnings
To suppress warnings generated by our code, we’ll use this code block
# To suppress warnings generated by the code
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
warnings.filterwarnings('ignore')Import Libraries
import pandas as pd
from sklearn.linear_model import LinearRegressionData - Task 1
- Modified version of car mileage dataset. Available at https://archive.ics.uci.edu/ml/datasets/auto+mpg
- Modified version of diamonds dataset. Available at https://www.openml.org/search?type=data&sort=runs&id=42225&status=active
Load
# the data set is available at the url below.
URL = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0231EN-SkillsNetwork/datasets/mpg.csv"
# Load data with: read_csv function into a pandas dataframe.
df = pd.read_csv(URL)
# Review the data
# df.sample(5)| MPG | Cylinders | Engine Disp | Horsepower | Weight | Accelerate | Year | Origin | |
|---|---|---|---|---|---|---|---|---|
| 303 | 27.2 | 4 | 141.0 | 71 | 3190 | 24.8 | 79 | European |
| 126 | 14.0 | 8 | 304.0 | 150 | 4257 | 15.5 | 74 | American |
| 150 | 20.0 | 6 | 232.0 | 100 | 2914 | 16.0 | 75 | American |
| 224 | 25.5 | 4 | 140.0 | 89 | 2755 | 15.8 | 77 | American |
| 175 | 22.0 | 4 | 121.0 | 98 | 2945 | 14.5 | 75 | European |
Count Rows & Columns
df.shape(392, 8)Scatter Plot Data
- First we’ll plot HP vs MPG
df.plot.scatter(x = "Horsepower", y = "MPG")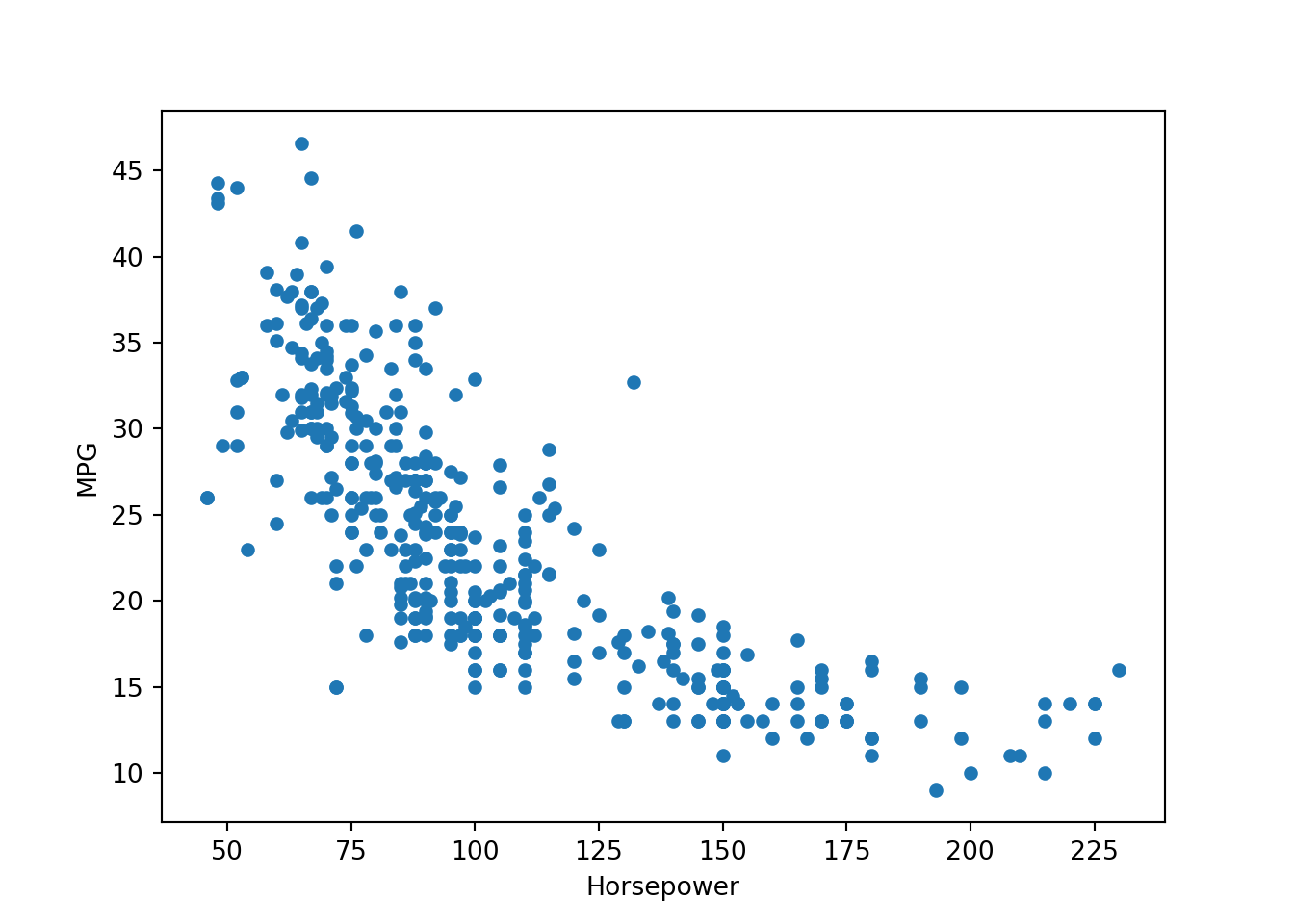
- Now let’s plot Weight vs MPG
df.plot.scatter(x = "Weight", y = "MPG")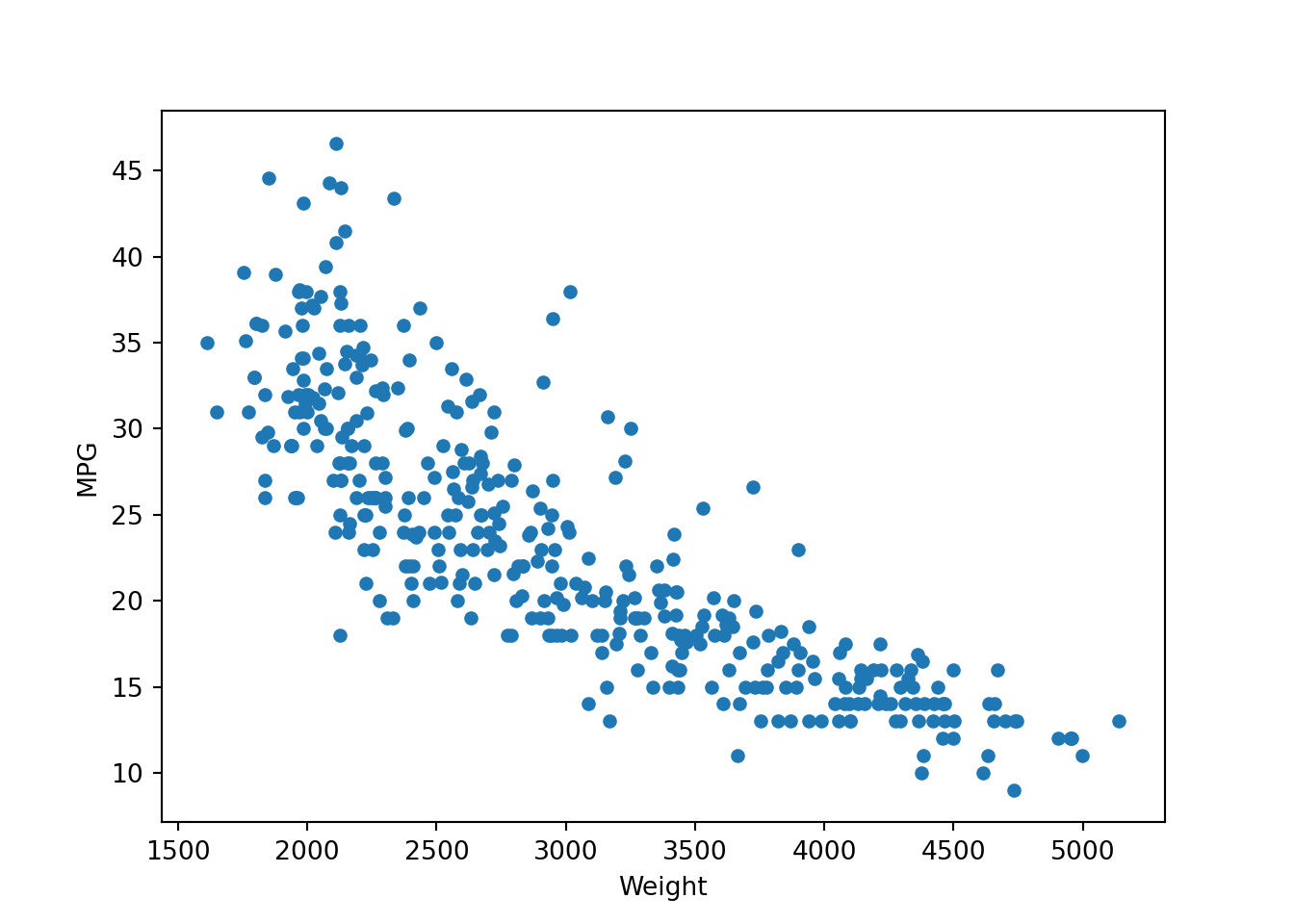
Define Targets/Features - Task 2
Target
In LR models we aim to predict the Target value given Input/Data.
So, in this example we are trying to find the MPG which is the Target Column in our table
target = df['MPG']Features
The feature(s) is/are the data columns we will provide our model with as input from which we want it to predict the Target Value/Column
In our example let’s provide the model with these Features, and see how accurate it will be in predicting the MPG
- Horsepower
- Weight
features = df[['Horsepower', 'Weight']]Build LR Model - Task 3
Define LR Model
lr = LinearRegression()Train/Fit LR Model
Let’s train it. The response will be
- LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
lr.fit(features,target)LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
Evaluate Model & Predict - Task 4
Now that the model has been trained on the data/features provided above, let’s evaluate it
Score
The higher the better in LR Models
#Higher the score, better the model.
lr.score(features,target)0.7063752737298348Predict
Let’s make some predictions:
- What’s the GPM for a car with HP=100 and Weight=2000
- As you see: 29.3216098 miles per gallon is the mileage of a car with HorsePower = 100 and Weight = 2000
lr.predict([[100,2000]])array([29.3216098])