Classification
.
Recap
Remember there are two types of supervised learning techniques: Classification and Regression.
Classification is the process of predicting a class label or category. We take an input x and we predict a value of y based on choices given for y
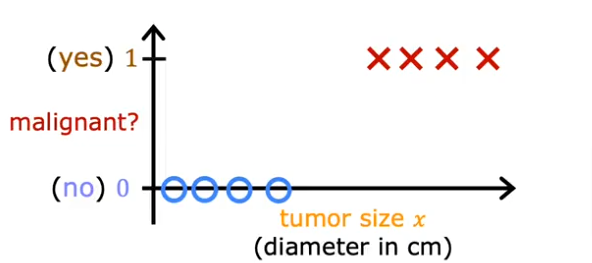
- Classification techniques are used for predicting the class or category of a case. For example, if a cell is benign or malignant, or whether a customer will churn.
- For example, “Will I pass or fail my biology test”?
- In this case, there are only two outcomes, and I can only be bucketed in one at a time; for example, either I will pass, or I will fail the exam.
- Classification answers the question “What category does this fall into?”
- On the other hand, regression answers “What will my biology exam score be?”
Classification is the process of predicting an outcome, known as a “class,” based on some given inputs. What are inputs?
Inputs
Let’s use our pass or fail example, “Will I pass or fail my biology exam?”
Input variables are independent variables or features that are used to make predictions.
- It can be one variable, for example, “Average score on previous biology tests” or
- multiple variables including the following features - “Percent of classes attended” - “Number of hours studied.”

So the direction of the arrow shows how the input variable helps answer the question, which then predicts the outcome of whether I will pass or fail. This means that the outcome of passing or failing my biology exam is dependent on these input variables and knowing these values can give me information about the outcome of the test.
Binary Classification
The previous example focused on predicting two classes: Pass or fail
Another example is classifying if an email is spam or not spam.
When you have only two classes, it is called binary classification. We designate them as 1 or 0, with 1 being the positive(true) or presence and 0 the negative(false) or absence
Multiclass Classification
When you have three or more classes, it is called multiclass classification. Predicting the handwritten digits from 1 to 9, or predicting if a piece of fruit is an apple, orange, or mango.
Before we go any further, let’s go through these very important terminologies.
Classifier
A classifier is a machine learning algorithm that is used to solve the classification problem.
Feature
A feature is the independent variable that is used as an input in the model.
Evaluation
When you ‘evaluate’ a model, you are validating how well it has performed.
Algorithms
If we use LR on classes we end up with something like this and we can set a threshold (vertical line) anything to the left we can classify as 0 and to the right as 1.
- It might look reasonable but in reality it is not. If we have a y value all the way to the right of the plot below.
- Because the value to the far right will shift the LR line as you see with the green line
- And now the predictions using the threshold will not yield reliable results
- As you see the decision boundary has shifted as shown in the green vertical line
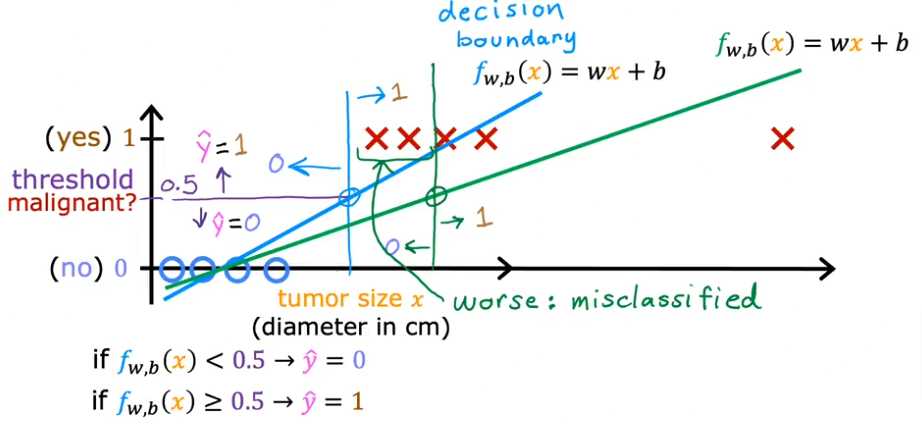
So LR is not the way to predict classes/category. So we use other algorithms: you can divide classification algorithms into two. The most popular algorithm to tackle this, is the Logistic Regression which we’ll cover later.
Lazy Learner
A “lazy learner” doesn’t have a training phase per se, as it waits to have a test data set before making predictions.
- This means that it doesn’t generalize the model, therefore taking longer to predict.
KNN
A very popular example is the k-nearest neighbor algorithm, also known as KNN. KNN classifies the unknown data points by finding the most common classes in the k-nearest examples. Then, it finds the closest match to the test data.
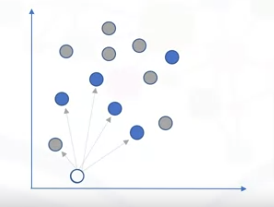
If we continue using our exam grade example.
- Consider when two sets of points are given on a plane.
- One set is a class of grey circles that represent students who failed, and the other set is a class of blue circles that represent the students who passed.
- If I appear on the plane and want to predict if I will pass or fail, KNN finds the k most similar students to me based on some inputs.
- Then, it calculates the distance from them, with k being the number of neighbors it checks.
- Let’s assume k is 5.
- K will classify my grade as a “pass,” using a majority vote approach.
- Here, four out of five of my ”neighbors” are classified as “pass.”
Eager Learner
The second kind of learner is the “eager learner.”
The eager learner spends a lot of time training and generalizing the model, so it spends less time predicting the test data set.
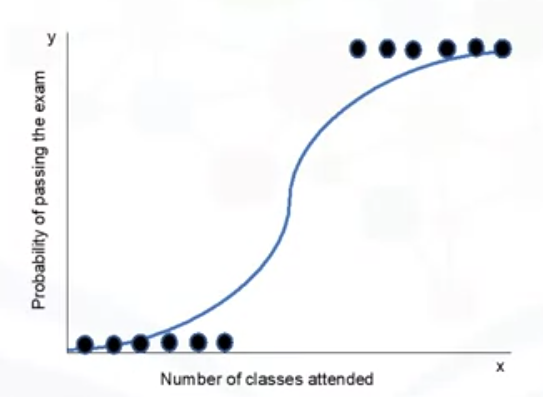
Logistic Regression
You can also use logistic regression. This model is used to predict the probability of a class.
For example, given the number of classes I attended, what is the probability I will pass or fail my biology exam?
Decision Trees
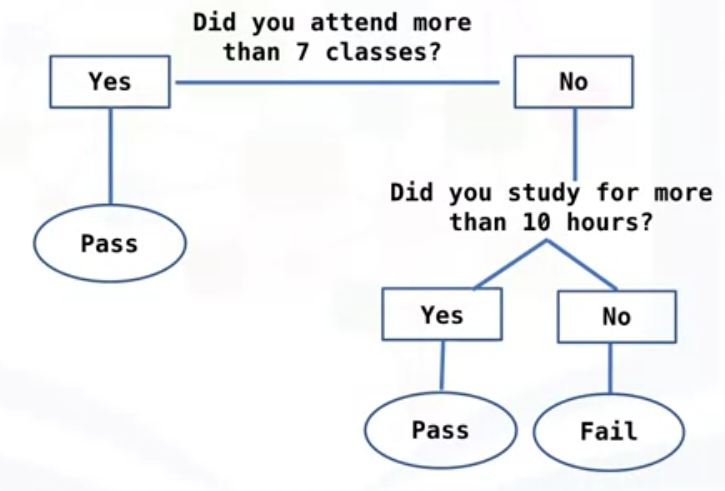
Finally, you have decision trees, which are tree-like algorithms that use an ”If-then” rule.
In this example, it classifies if you will pass or fail based on some rules.
Other advanced algorithms are