import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from utils import *Decision Trees
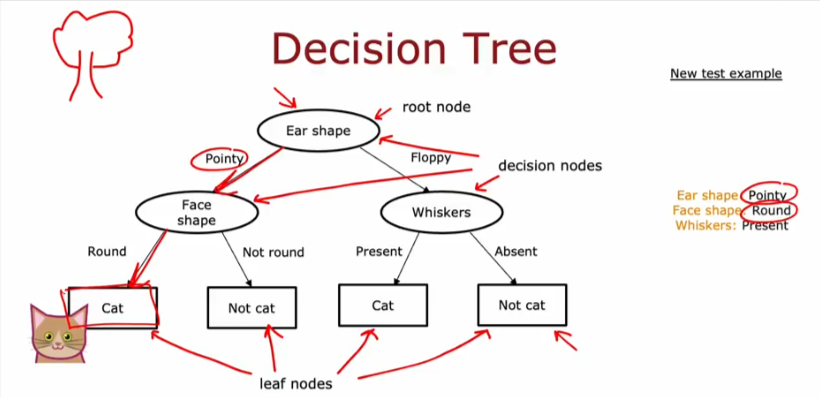
Studied DTs many years ago so I will not go through the basics too much, and if you’ve gotten so far, the logic behind them is pretty simple and logical and doesn’t need much explanation. Heck you probably covered decision trees in Psychology classes…. Here is an example
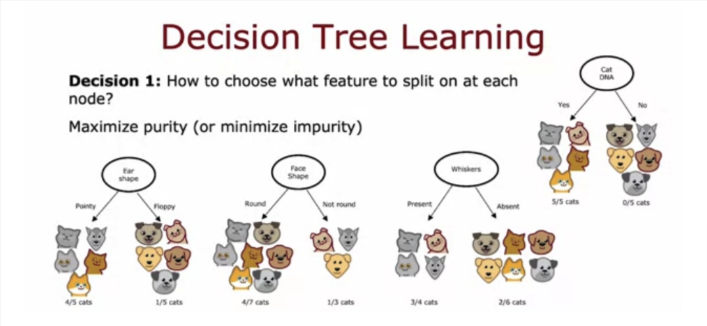
Purity
Splitting
So how do you decide which feature to split on to maximize purity. Purity is when the leaf node has 5/5 being cats or 0/5 being cats.
Stop splitting
Aside as to which to feature to split on, we need to decide when to stop splitting. Here are some ideas as to when to stop:
- When a node is 100% one class
- When splitting a node will result in the tree exceeding a max depth
- When the number of examples in a node is below a certain threshold
Entropy
Entropy as a measure of impurity
- The value of entropy is highest at 1 when the set of samples is 50/50
- When the samples are either all cats or dogs then the entropy is 0
- The closer the entropy is to 1 the more IMPURE the set is, and as you see below, 0.92 is more impure than 0.65

Formula
Let’s make a formula out of entropy so we can calculate it
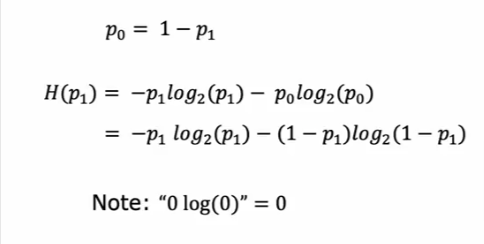
Information Gain
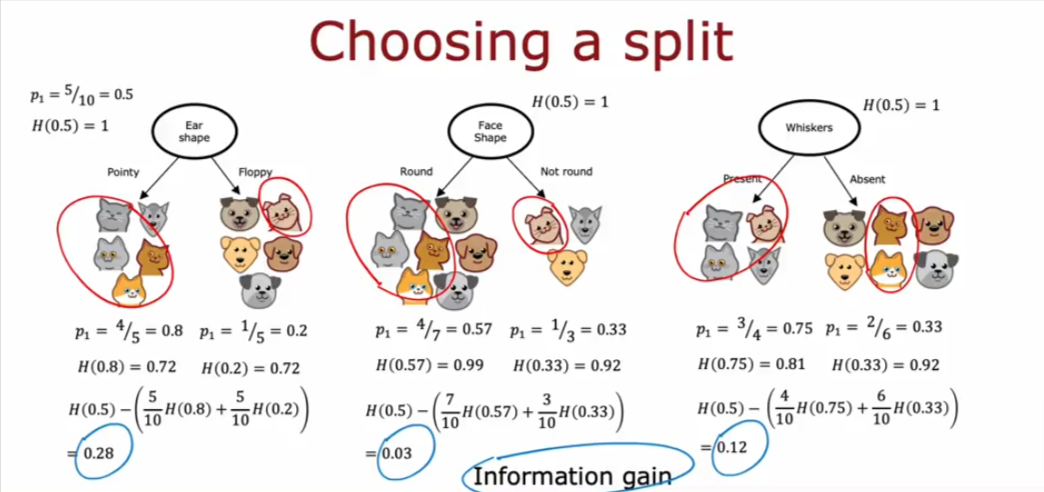
- So we can decide where to split a tree based on information gain
- We decide when to stop splitting based on information gain as well (one option)
- Here is the definition of information gain
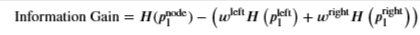

- H being the entropy defined above
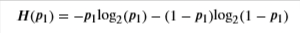
%matplotlib widget
_ = plot_entropy()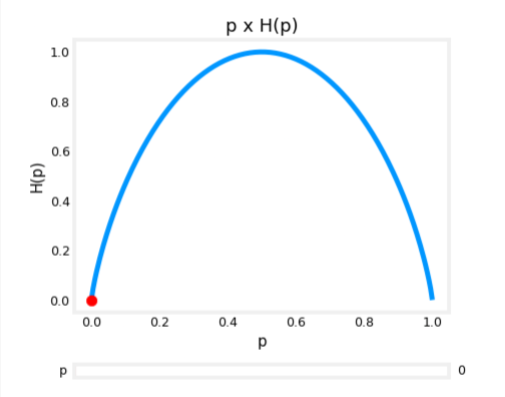
Data
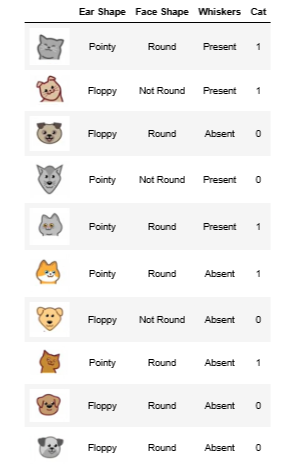
One Hot Encoding
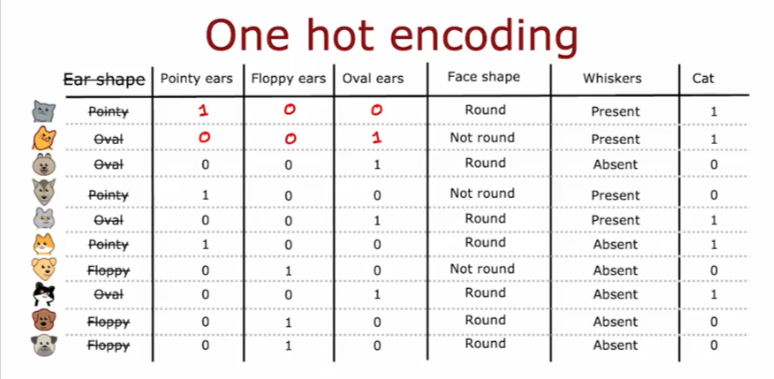
Simply put: if we have a feature with more than a binary option for value we can split that feature into multiple features so we can have a binary choice for each new feature. This way we can either use a decision tree model or a NN model.
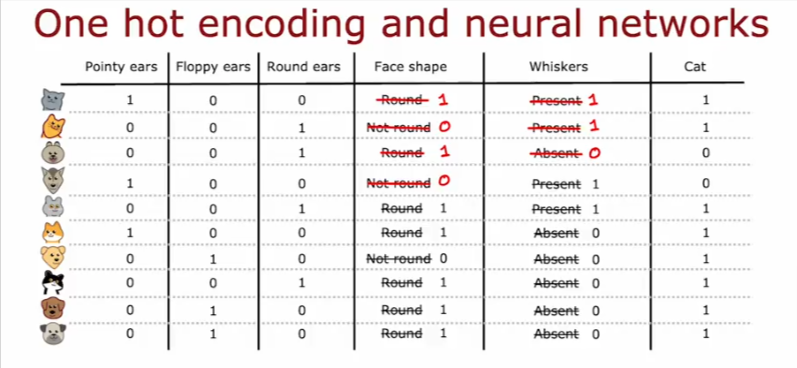
We can also convert the other features into binary values as well as seen below for NN
Continuous Features
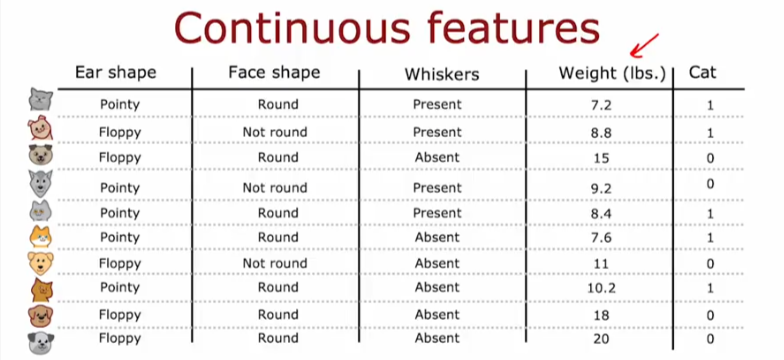
What if we introduce a new feature weight which is of continuous value and not binary?
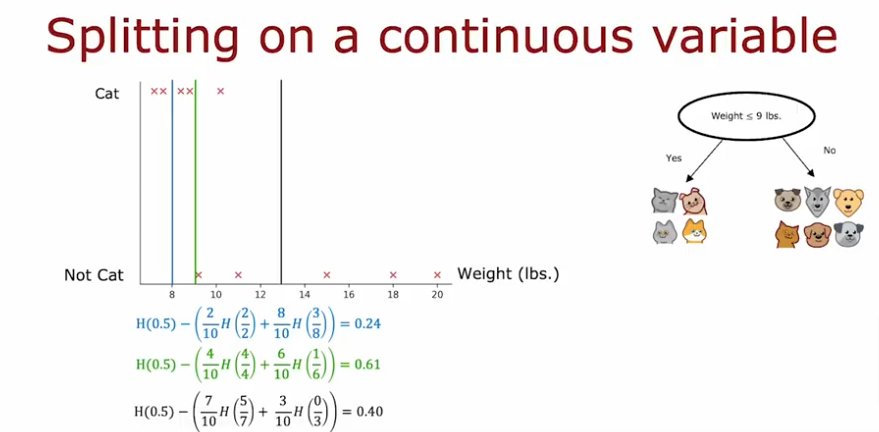
- So we can plot the values and split the dataset based on what will give us the greatest information gain value
- One choice is to take all the values around the midpoint and test for the value of the information gain (in the example below it would be to test 9 out of the 10 values for largest gain)
- If the gain is higher than any other gain for other features then you decide to split on the highest if this is the highest
- Here we can see how we can do that
Regression & D Trees
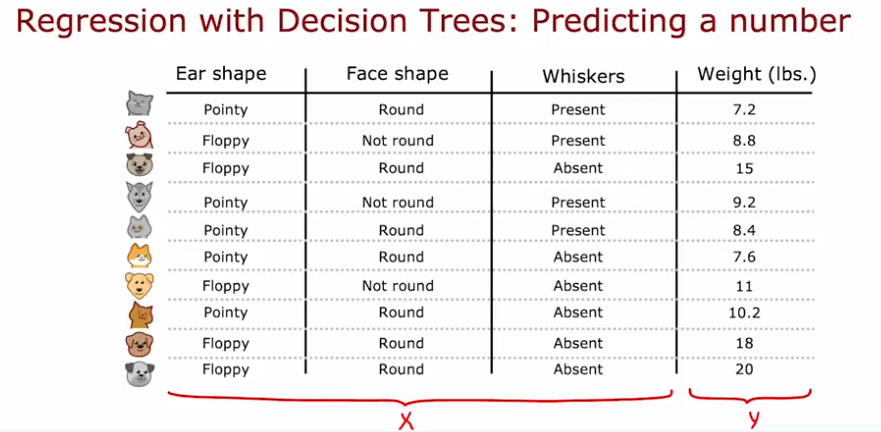
What if we want to predict the weight of the animal instead of using it as a feature, we want to use it as y (label)?
Average Variance
We will use the average variance of the weights for each sample to decide on the split as opposed to information gain values

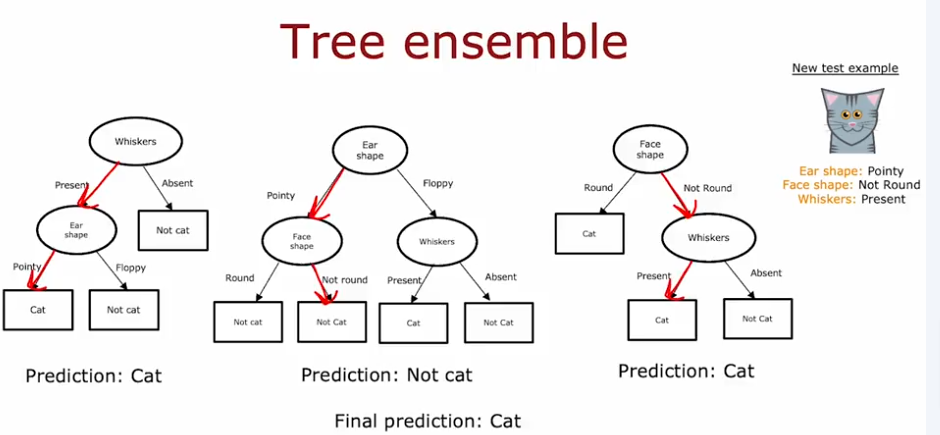
Tree Ensembles
DT are very sensitive to small changes in the data. Let’s say for example we change one sample, where we take one can and change it to floppy ears, whiskers, and floppy ears as we see below that will completely change the feature to use for splitting the data at the node from ear shape to whiskers:

So the solution would be to train a whole set of decision trees instead of one: Tree Ensemble
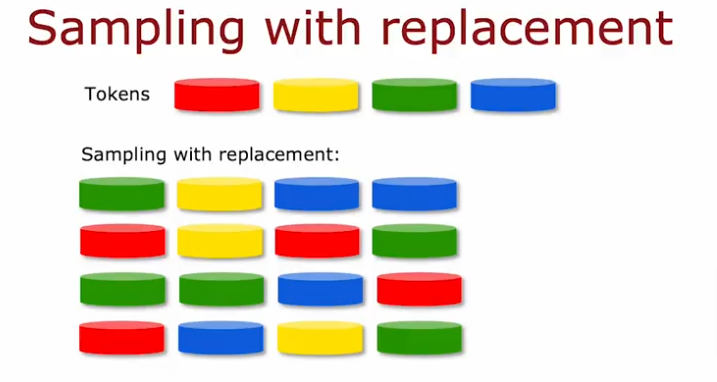
Sampling with Replacement
So you have to create a training set by pulling one training sample and replace, pull another one and replace it, pick another one to pull out and replace, pick again and continue.
DT vs NN
Decision Tree
- Work well on tabular (structured/spreadsheet data)
- Not recommended for unstructured data (images, audio, text)
- Fast
- Small decision trees may be human interpretable but hundreds of them are easier to use DT Ensemble
NN
- Works well on all types of data structured or not
- May be slower than DT
- Works with transfer learning
- Working on a system of multiple models it is easier to chain together NN than DT